Diperbarui oleh Shenghou Ma, Mei 2013
Pada pertemuan Scala Days 2011, Robert Hundt mempresentasikan sebuah makalah berjudul Loop Recognition in C++/Java/Go/Scala. Makalah tersebut mengimplementasikan algoritme pencarian pengulangan (loop finding) khusus, yang biasa digunakan dalam analisis alur pada sebuah compiler, dalam C++, Go, Java, Scala, dan menggunakan program tersebut untuk mengambil kesimpulan tentang kinerja pada bahasa-bahasa pemrograman tersebut. Program Go yang dipresentasikan dalam makalah tersebut berjalan cukup lambat, sehingga membuatnya sebagai sebuah contoh yang bagus untuk memperlihatkan tentang perkakas profil Go "go tool pprof" yang dapat membuat sebuah program yang lambat menjadi cepat.
Dengan menggunakan perkakas profil Go untuk mengidentifikasi dan memperbaiki
pemampatan (bottleneck), kita dapat membuat program Go yang berjalan lebih
cepat dan menggunakan memori yang 6x lebih sedikit.
(Pembaruan: Dikarenakan optimasi terbaru pada libstdc++ dalam gcc,
pengurangan memori hanya menjadi 3.7x saja.)
Makalah Hundt tidak menyebut versi C, Go, Java, dan Scala yang dia gunakan.
Dalam artikel ini, kita akan menggunakan _snapshot_ mingguan terakhir dari
_compiler_ Go `6g` dan versi `g` yang ada pada distribusi Ubuntu Natty.
(Kita tidak akan memakai Java atau Scala, karena kita tidak memiliki keahlian
yang cukup untuk menulis program yang efisien pada bahasa tersebut, sehingga
pembandingannya nanti menjadi tidak adil.
Secara C adalah bahasa paling cepat dalam makalah tersebut, pembandingan
dengan C saja sudah cukup.)
(Pembaruan: Dalam pembaruan artikel ini, kita akan menggunakan snapshot
terakhir dari compiler Go pada arsitektur amd64 dan versi terakhir dari
g++ 4.8.0, yang dirilis pada Maret 2013.)
$ go version go version devel +08d20469cc20 Tue Mar 26 08:27:18 2013 +0100 linux/amd64 $ g++ --version g++ (GCC) 4.8.0 Copyright (C) 2013 Free Software Foundation, Inc. ... $
Program tersebut berjalan pada komputer dengan 3.4GHz Core i7-2600 CPU dan 16 GB RAM di atas Gentoo Linux kernel 3.8.4-gentoo. Mesin tersebut berjalan dengan mematikan frekuensi CPU,
$ sudo bash
# for i in /sys/devices/system/cpu/cpu[0-7]
do
echo performance > $i/cpufreq/scaling_governor
done
#
Kita telah mengambil
program benchmark dari Hundt
dalam C++ dan Go, menggabungkan setiap sumber kode dalam sebuah sumber berkas
tersendiri dan menghapus semua keluaran kecuali sebuah baris.
Kita akan ukur waktu program menggunakan utilitas time pada Linux dengan
format yang menampilkan waktu di sisi user, waktu nyata, dan
maksimum penggunaan memori:
$ cat xtime #!/bin/sh /usr/bin/time -f '%Uu %Ss %er %MkB %C' "$@" $ $ make havlak1cc g++ -O3 -o havlak1cc havlak1.cc $ ./xtime ./havlak1cc # of loops: 76002 (total 3800100) loop-0, nest: 0, depth: 0 17.70u 0.05s 17.80r 715472kB ./havlak1cc $ $ make havlak1 go build havlak1.go $ ./xtime ./havlak1 # of loops: 76000 (including 1 artificial root node) 25.05u 0.11s 25.20r 1334032kB ./havlak1 $
Program C++ berjalan selama 17.80 detik dan menggunakan 700 MB memori. Program Go berjalan selama 25.20 detik dan menggunakan 1302 MB memori. (Pengukuran ini tidak bisa disamakan dengan hasil dari makalah tersebut, tetapi inti dari artikel ini adalah mengeksplorasi bagaimana menggunakan "go tool pprof", bukan mengulangi hasil dari makalah.)
Untuk mulai men-tuning program Go, kita harus menyalakan profil.
Seandainya kode tersebut ditulis menggunakan fungsi benchmark dari
paket Go testing,
kita dapat menggunakan opsi standar dari gotest yaitu -cpuprofile dan
-memprofile.
Dalam program seperti ini, kita harus mengimpor runtime/pprof dan
menambahkan beberapa baris kode:
var cpuprofile = flag.String("cpuprofile", "", "write cpu profile to file")
func main() {
flag.Parse()
if *cpuprofile != "" {
f, err := os.Create(*cpuprofile)
if err != nil {
log.Fatal(err)
}
pprof.StartCPUProfile(f)
defer pprof.StopCPUProfile()
}
...
Kode yang baru mendefinisikan sebuah opsi cpuprofile, memanggil
pustaka Go flag
untuk memindai opsi pada baris perintah saat program dijalankan, dan kemudian,
jika opsi cpuprofile telah di-set pada baris perintah,
jalankan profil CPU
yang kemudian disimpan ke dalam berkas yang ditentukan.
Fungsi profil (profiler) tersebut butuh memanggil
StopCPUProfile
untuk memastikan penulisan ke berkas terjadi sepenuhnya, sebelum program
berhenti;
kita menggunakan defer untuk memastikan hal tersebut terjadi saat main
telah selesai.
Setelah menambahkan kode tersebut, kita dapat jalankan program dengan opsi
-cpuprofile dan kemudian menjalankan go tool pprof untuk
menginterpretasikan hasil profil.
$ make havlak1.prof ./havlak1 -cpuprofile=havlak1.prof # of loops: 76000 (including 1 artificial root node) $ go tool pprof havlak1 havlak1.prof Welcome to pprof! For help, type 'help'. (pprof)
Program "go tool pprof" adalah varian dari
Google pprof C++ profiler.
Perintah yang paling penting yaitu topN, yang menampilkan N sampel teratas
dalam profil:
(pprof) top10
Total: 2525 samples
298 11.8% 11.8% 345 13.7% runtime.mapaccess1_fast64
268 10.6% 22.4% 2124 84.1% main.FindLoops
251 9.9% 32.4% 451 17.9% scanblock
178 7.0% 39.4% 351 13.9% hash_insert
131 5.2% 44.6% 158 6.3% sweepspan
119 4.7% 49.3% 350 13.9% main.DFS
96 3.8% 53.1% 98 3.9% flushptrbuf
95 3.8% 56.9% 95 3.8% runtime.aeshash64
95 3.8% 60.6% 101 4.0% runtime.settype_flush
88 3.5% 64.1% 988 39.1% runtime.mallocgc
Saat profil CPU berjalan, program Go berhenti sekitar 100 kali per detik dan
mencatat sebuah sampel yang berisi penghitungan program pada stack dari
goroutine yang sedang dieksekusi.
Profil yang dihasilkan berisi 2525 sampel, jadi ia berjalan sekitar 25 detik.
Pada keluaran "go tool pprof", setiap fungsi yang tercatat dalam sampel
dicetak per baris.
Dua kolom pertama menampilkan jumlah sampel saat fungsi berjalan (bukan
dari menunggu fungsi untuk selesai), dalam hitungan mentah dan sebagai
persentase dari total sampel.
Contohnya, fungsi runtime.mapaccess1_fast64 dicatat berjalan dalam 298
sampel, atau 11.8% dari keseluruhan sampel.
Keluaran dari top10 diurut berdasarkan hitungan mentah sampel tersebut.
Kolom ketiga menampilkan total eksekusi dari fungsi-fungsi tersebut saat
pencatatan: tiga baris pertama menghabiskan 32.4% dari total sampel.
Kolom keempat dan kelima menampilkan jumlah sampel di mana fungsi muncul
(baik sedang berjalan atau menunggu selesai).
Fungsi main.FindLoops berjalan dalam 10.6% dari sampel, tetapi ia berada
dalam stack pemanggilan (baik fungsi itu sendiri atau ada fungsi lain yang
dipanggil saat berjalan) dalam 84.1% dari sampel.
Untuk mengurut berdasarkan kolom empat dan lima, gunakan opsi -cum (untuk
kumulatif):
(pprof) top5 -cum
Total: 2525 samples
0 0.0% 0.0% 2144 84.9% gosched0
0 0.0% 0.0% 2144 84.9% main.main
0 0.0% 0.0% 2144 84.9% runtime.main
0 0.0% 0.0% 2124 84.1% main.FindHavlakLoops
268 10.6% 10.6% 2124 84.1% main.FindLoops
(pprof) top5 -cum
Seharusnya total untuk main.FindLoops dan main.main adalah 100%, tetapi
setiap sampel stack hanya mengikutkan 100 stack frame terbawah;
selama sekitar seperempat dari sampel, fungsi rekursif main.DFS
100 frame lebih dalam dari main.main sehingga penelusuran yang komplit
dipotong.
Sampel stack trace berisi data yang lebih menarik tentang relasi pemanggilan
fungsi daripada daftar teks yang ditampilkan di atas.
Perintah web membuat sebuah grafik berdasarkan data profil dalam format SVG
dan memuatnya lewat peramban.
(Terdapat juga perintah gv yang membuat berkas PostScript dan membukanya
menggunakan Ghostview.
Untuk kedua perintah tersebut, Anda butuh memasang program
graphviz
.)
(pprof) web
Potongan kecil dari grafik berbentuk seperti ini:
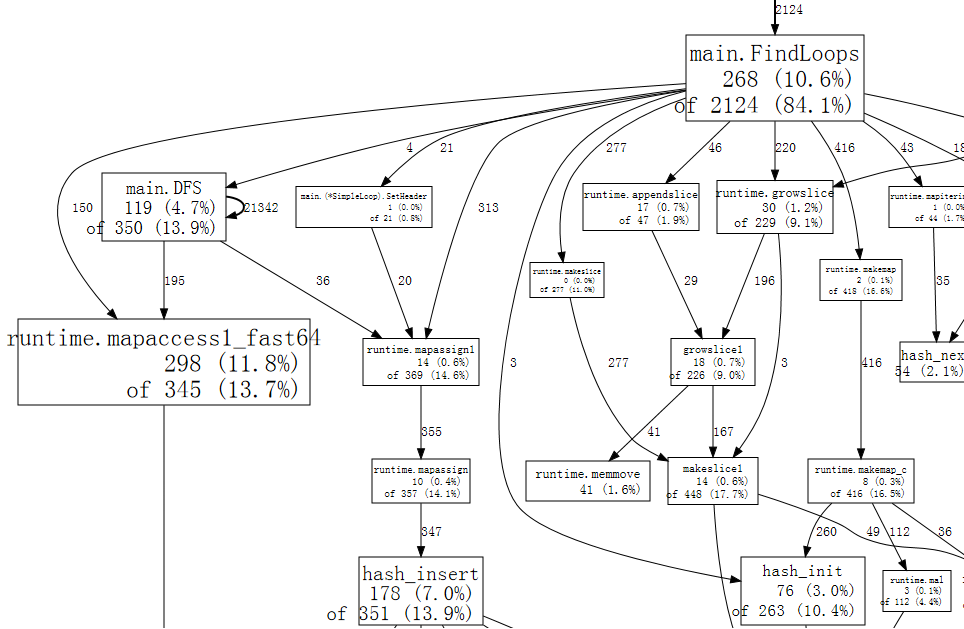
Setiap kotak dalam grafik berkorespondensi ke sebuah fungsi, dan ukuran kotak
tersebut sesuai dengan jumlah sampel di mana fungsi berjalan.
Panah dari kotak X ke Y mengindikasikan bahwa X memanggil Y;
angka pada panah yaitu jumlah berapa kali pemanggilan tercatat dalam
sampel.
Jika sebuah pemanggilan fungsi muncul beberapa kali dalam sebuah sampel,
misalnya selama pemanggilan fungsi yang rekursif, jumlah kemunculan
ditampilkan dengan lebar dari panah.
Hal ini menjelaskan 21342 pada panah dari main.DFS ke dirinya sendiri.
Secara sekilas, kita dapat melihat bahwa program menghabiskan banyak waktunya
pada operasi hash, yang berkorespondensi ke penggunaan nilai map.
Kita dapat memberitahu perintah web supaya menggunakan hanya sampel yang
mengikutkan fungsi tertentu, seperti runtime.mapaccess1_fast64, yang akan
membersihkan beberapa kotak pada grafik:
(pprof) web mapaccess1
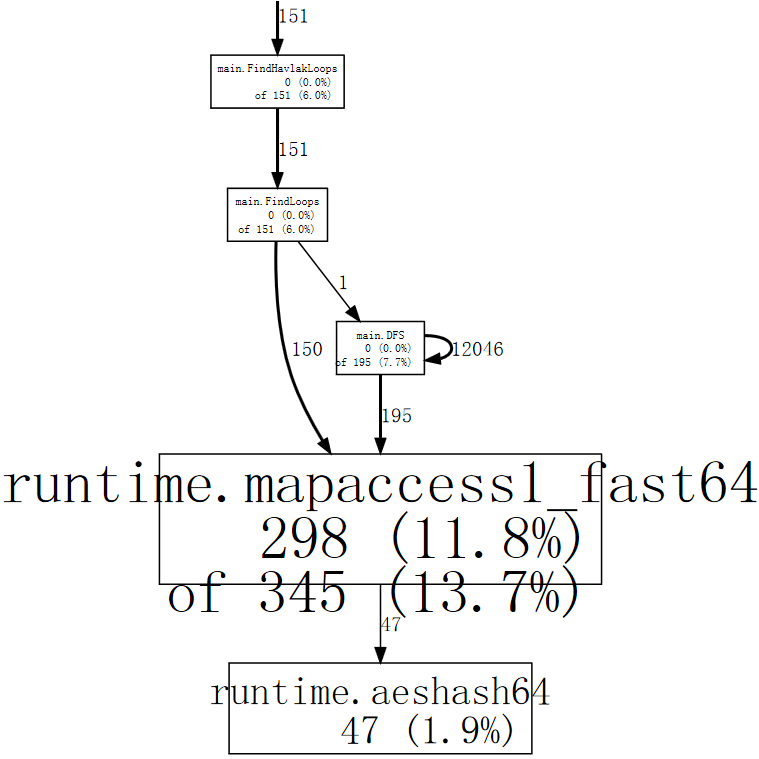
Jika dilihat, pemanggilan ke runtime.mapaccess1_fast64 dilakukan oleh
main.FindLoops dan main.DFS.
Sekarang setelah kita punya gambaran, saatnya kita melihat profil fungsi lebih
rinci.
Pertama, mari kita lihat main.DFS, karena fungsinya cukup singkat:
(pprof) list DFS
Total: 2525 samples
ROUTINE ====================== main.DFS in /home/rsc/g/benchgraffiti/havlak/havlak1.go
119 697 Total samples (flat / cumulative)
3 3 240: func DFS(currentNode *BasicBlock, nodes []*UnionFindNode, number map[*BasicBlock]int, last []int, current int) int {
1 1 241: nodes[current].Init(currentNode, current)
1 37 242: number[currentNode] = current
. . 243:
1 1 244: lastid := current
89 89 245: for _, target := range currentNode.OutEdges {
9 152 246: if number[target] == unvisited {
7 354 247: lastid = DFS(target, nodes, number, last, lastid+1)
. . 248: }
. . 249: }
7 59 250: last[number[currentNode]] = lastid
1 1 251: return lastid
(pprof)
Daftar tersebut menampilkan kode sumber dari fungsi DFS (sebenarnya untuk
setiap fungsi yang cocok dengan regular expression DFS, kebetulan hanya
ditemukan satu saja).
Tiga kolom pertama adalah total sampel yang diambil saat menjalankan baris
tersebut, total sampel yang diambil saat menjalankan baris tersebut atau dari
kode yang dipanggil dari baris tersebut (kumulatif), dan nomor baris pada
berkas kode.
Perintah disasm membongkar fungsi tersebut menjadi perintah-perintah
assembly bukan menampilkan daftar sumber kode;
bila jumlah sampel cukup perintah tersebut dapat membantu Anda melihat
instruksi mana yang memakan biaya.
Perintah weblist menggabungkan kedua mode tersebut: ia memperlihatkan
daftar sumber kode
dan pada saat sebuah baris di klik ia akan menampilkan assembly dari
baris tersebut.
Secara kita telah mengetahui bahwa waktu program banyak dihabiskan untuk
pencarian pada map yang diimplementasikan oleh fungsi hash, kita akan
memperhatikan kolom kedua.
Sebagian besar waktu dihabiskan pada pemanggilan rekursif ke DFS (baris
247), seperti yang diharapkan.
Mengindahkan rekursif, tampaknya waktu dihabiskan mengakses ke map number
pada baris 242, 246, dan 250.
Untuk pencarian khusus tersebut, menggunakan sebuah map bukanlah pilihan
yang tepat.
Dalam sebuah compiler, struktur blok memiliki seurutan angka unik.
Kita dapat mengganti map[*BasicBlock]int dengan []int, sebuah slice yang
di-indeks oleh nomor blok.
Tidak perlu menggunakan sebuah map bila array atau slice bisa digunakan.
Mengubah number dari sebuah map menjadi slice membutuhkan penyuntingan tujuh
baris dalam program dan membuat program dua kali lebih cepat:
$ make havlak2 go build havlak2.go $ ./xtime ./havlak2 # of loops: 76000 (including 1 artificial root node) 16.55u 0.11s 16.69r 1321008kB ./havlak2 $
Kita jalankan profiler kembali untuk memastikan main.DFS tidak lagi
menghabiskan banyak waktu saat dijalankan:
$ make havlak2.prof
./havlak2 -cpuprofile=havlak2.prof
# of loops: 76000 (including 1 artificial root node)
$ go tool pprof havlak2 havlak2.prof
Welcome to pprof! For help, type 'help'.
(pprof)
(pprof) top5
Total: 1652 samples
197 11.9% 11.9% 382 23.1% scanblock
189 11.4% 23.4% 1549 93.8% main.FindLoops
130 7.9% 31.2% 152 9.2% sweepspan
104 6.3% 37.5% 896 54.2% runtime.mallocgc
98 5.9% 43.5% 100 6.1% flushptrbuf
(pprof)
Baris main.DFS tidak muncul lagi dalam profil, dan beberapa bagian dari
runtime program juga telah hilang.
Sekarang program menghabiskan waktunya dengan mengalokasikan memori dan
garbage collecting (runtime.mallocgc, yang mengalokasikan dan menjalankan
garbage collection secara periodik, menghabiskan 54.2% dari waktu
keseluruhan).
Untuk mengetahui kenapa garbage collector terlalu sering berjalan, kita
harus mengetahui bagian mana yang mengalokasikan memori.
Salah satu cara yaitu dengan menambahkan profil memori ke dalam program.
Kita akan atur supaya bila opsi -memprofile diberikan, program akan berhenti
setelah satu iterasi pencarian, menulis profil memori, dan berhenti:
var memprofile = flag.String("memprofile", "", "write memory profile to this file")
...
FindHavlakLoops(cfgraph, lsgraph)
if *memprofile != "" {
f, err := os.Create(*memprofile)
if err != nil {
log.Fatal(err)
}
pprof.WriteHeapProfile(f)
f.Close()
return
}
Kita panggil program dengan opsi -memprofile supaya menulis profil:
$ make havlak3.mprof go build havlak3.go ./havlak3 -memprofile=havlak3.mprof $
(Lihat
perubahan dari havlak2)
Kita gunakan "go tool pprof" dengan cara yang sama. Sekarang sampel-sampel tersebut berisi alokasi memori, bukan waktu penggunaan CPU lagi.
$ go tool pprof havlak3 havlak3.mprof
Adjusting heap profiles for 1-in-524288 sampling rate
Welcome to pprof! For help, type 'help'.
(pprof) top5
Total: 82.4 MB
56.3 68.4% 68.4% 56.3 68.4% main.FindLoops
17.6 21.3% 89.7% 17.6 21.3% main.(*CFG).CreateNode
8.0 9.7% 99.4% 25.6 31.0% main.NewBasicBlockEdge
0.5 0.6% 100.0% 0.5 0.6% itab
0.0 0.0% 100.0% 0.5 0.6% fmt.init
(pprof)
Perintah "go tool pprof" melaporkan bahwa FindLoops telah mengalokasikan
sekitar 56.3 dari 82.4 MB memori yang digunakan;
CreateNode menggunakan 17.6 MB.
Untuk mengurangi beban, profil memori hanya mencatat informasi sekitar satu
blok per setengah megabyte yang dialokasikan ("1-dalam-524288 laju sample"), jadi
ini adalah perkiraan dari nilai sebenarnya.
Untuk mencari alokasi memori, kita dapat tampilkan daftar fungsi.
(pprof) list FindLoops
Total: 82.4 MB
ROUTINE ====================== main.FindLoops in /home/rsc/g/benchgraffiti/havlak/havlak3.go
56.3 56.3 Total MB (flat / cumulative)
...
1.9 1.9 268: nonBackPreds := make([]map[int]bool, size)
5.8 5.8 269: backPreds := make([][]int, size)
. . 270:
1.9 1.9 271: number := make([]int, size)
1.9 1.9 272: header := make([]int, size, size)
1.9 1.9 273: types := make([]int, size, size)
1.9 1.9 274: last := make([]int, size, size)
1.9 1.9 275: nodes := make([]*UnionFindNode, size, size)
. . 276:
. . 277: for i := 0; i < size; i++ {
9.5 9.5 278: nodes[i] = new(UnionFindNode)
. . 279: }
...
. . 286: for i, bb := range cfgraph.Blocks {
. . 287: number[bb.Name] = unvisited
29.5 29.5 288: nonBackPreds[i] = make(map[int]bool)
. . 289: }
...
Tampaknya pemampatan terjadi sama seperti sebelumnya: menggunakan map
padahal struktur data sederhana bisa menggantikan.
FindLoops mengalokasikan sekitar 29.5 MB map.
Selain itu, jika kita jalankan "go tool pprof" dengan opsi —inuse_objects,
ia akan melaporkan penghitungan alokasi bukan ukurannya:
$ go tool pprof --inuse_objects havlak3 havlak3.mprof
Adjusting heap profiles for 1-in-524288 sampling rate
Welcome to pprof! For help, type 'help'.
(pprof) list FindLoops
Total: 1763108 objects
ROUTINE ====================== main.FindLoops in /home/rsc/g/benchgraffiti/havlak/havlak3.go
720903 720903 Total objects (flat / cumulative)
...
. . 277: for i := 0; i < size; i++ {
311296 311296 278: nodes[i] = new(UnionFindNode)
. . 279: }
. . 280:
. . 281: // Step a:
. . 282: // - initialize all nodes as unvisited.
. . 283: // - depth-first traversal and numbering.
. . 284: // - unreached BB's are marked as dead.
. . 285: //
. . 286: for i, bb := range cfgraph.Blocks {
. . 287: number[bb.Name] = unvisited
409600 409600 288: nonBackPreds[i] = make(map[int]bool)
. . 289: }
...
(pprof)
Secara ~200.000 map menghabiskan 29.5 MB, tampaknya alokasi awal dari map memakai sekitar 150 byte. Hal ini masuk akal bila map digunakan untuk menyimpan pasangan kunci-dan-nilai, tetapi tidak bila sebuah map digunakan sebagai pengganti dari kumpulan, seperti yang tampak di atas.
Alih-alih menggunakan map, kita dapat menggunakan slice sederhana untuk
menyimpan elemen-elemen tersebut.
Di semua kasus yang menggunakan map, sangat tidak mungkin bagi algoritme
menyimpan elemen yang duplikat, kecuali pada satu kasus.
Pada sisa kasus yang satu tersebut, kita dapat menulis sebuah varian dari
fungsi bawaan append:
func appendUnique(a []int, x int) []int {
for _, y := range a {
if x == y {
return a
}
}
return append(a, x)
}
Selain menulis fungsi tersebut, mengubah program Go menggunakan slice bukan map membutuhkan perubahan hanya pada beberapa baris kode.
$ make havlak4 go build havlak4.go $ ./xtime ./havlak4 # of loops: 76000 (including 1 artificial root node) 11.84u 0.08s 11.94r 810416kB ./havlak4 $
(Lihat
perubahan untuk havlak3)
Sekarang program kita 2.11x lebih cepat dari semula. Mari kita lihat profil CPU sekali lagi.
$ make havlak4.prof
./havlak4 -cpuprofile=havlak4.prof
# of loops: 76000 (including 1 artificial root node)
$ go tool pprof havlak4 havlak4.prof
Welcome to pprof! For help, type 'help'.
(pprof) top10
Total: 1173 samples
205 17.5% 17.5% 1083 92.3% main.FindLoops
138 11.8% 29.2% 215 18.3% scanblock
88 7.5% 36.7% 96 8.2% sweepspan
76 6.5% 43.2% 597 50.9% runtime.mallocgc
75 6.4% 49.6% 78 6.6% runtime.settype_flush
74 6.3% 55.9% 75 6.4% flushptrbuf
64 5.5% 61.4% 64 5.5% runtime.memmove
63 5.4% 66.8% 524 44.7% runtime.growslice
51 4.3% 71.1% 51 4.3% main.DFS
50 4.3% 75.4% 146 12.4% runtime.MCache_Alloc
(pprof)
Sekarang alokasi memori dan garbage collection (runtime.mallocgc)
menghabiskan 50.9% waktu program.
Cara lain untuk melihat kenapa sistem melakukan garbage collecting yaitu
dengan melihat alokasi yang mengakibatkan sejumlah koleksi, yang menyebabkan
waktu habis dalam mallocgc:
(pprof) web mallocgc
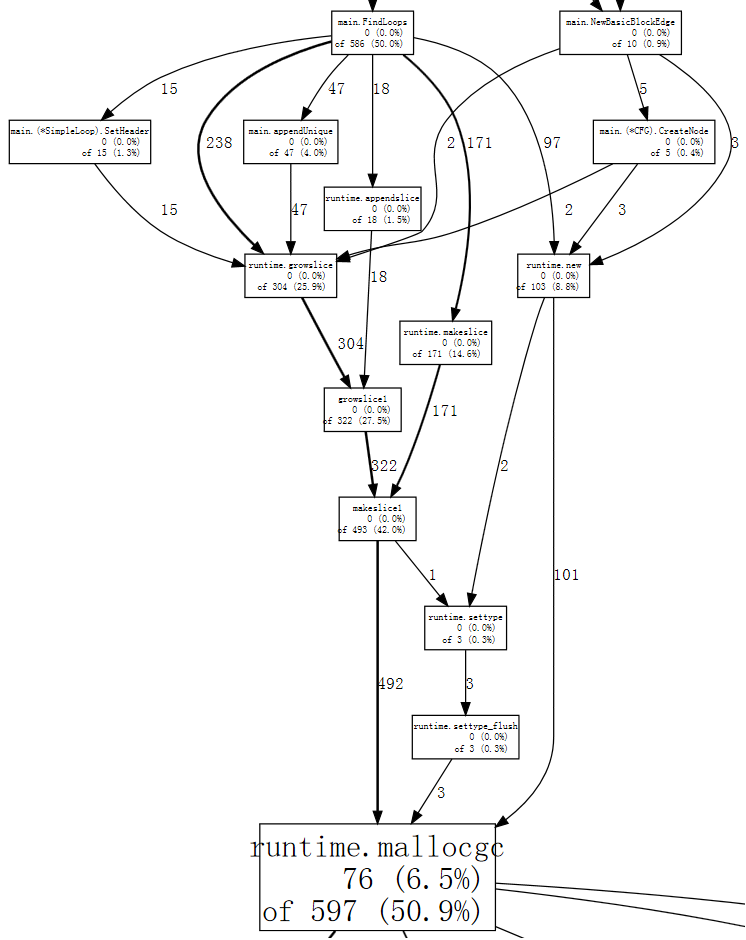
Sangat sukar melihat apa yang terjadi dalam grafik di atas, karena banyak node dengan jumlah sampel yang kecil mengaburkan yang besar. Kita dapat memberitahu "go tool pprof" untuk mengindahkan node-node yang paling tidak berisi 10% sampel:
$ go tool pprof --nodefraction=0.1 havlak4 havlak4.prof Welcome to pprof! For help, type 'help'. (pprof) web mallocgc
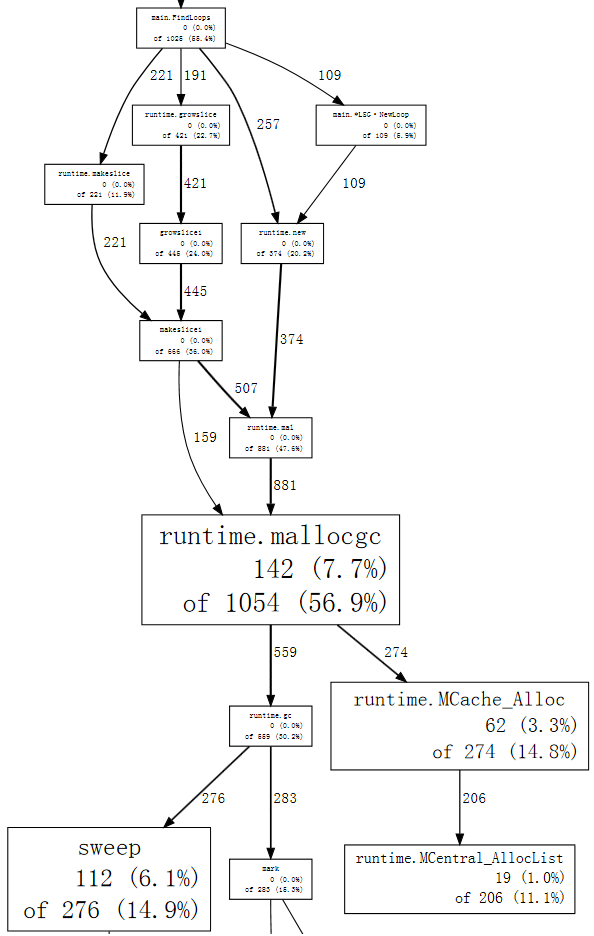
Sekarang kita dapat melihat panah yang besar dengan mudah, untuk melihat
FindLoops memicu kebanyakan garbage collection.
Jika kita panggil perintah list dengan parameter FindLoops kita dapat
dengan mudah melihat bahwa kebanyakan terjadi di awal:
(pprof) list FindLoops
...
. . 270: func FindLoops(cfgraph *CFG, lsgraph *LSG) {
. . 271: if cfgraph.Start == nil {
. . 272: return
. . 273: }
. . 274:
. . 275: size := cfgraph.NumNodes()
. . 276:
. 145 277: nonBackPreds := make([][]int, size)
. 9 278: backPreds := make([][]int, size)
. . 279:
. 1 280: number := make([]int, size)
. 17 281: header := make([]int, size, size)
. . 282: types := make([]int, size, size)
. . 283: last := make([]int, size, size)
. . 284: nodes := make([]*UnionFindNode, size, size)
. . 285:
. . 286: for i := 0; i < size; i++ {
2 79 287: nodes[i] = new(UnionFindNode)
. . 288: }
...
(pprof)
Setiap kali FindLoops dipanggil, ia mengalokasikan beberapa
struktur untuk pencatatan.
Secara hasil benchmark memanggil FindLoops 50 kali, hal ini menambah
sejumlah besar garbage, sehingga banyak pekerjaan untuk garbage collector.
Memiliki bahasa dengan garbage collector bukan berarti kita dapat
mengindahkan isu alokasi memori.
Dalam kasus ini, solusi sederhana yaitu dengan menggunakan sebuah cache
supaya setiap pemanggilan ke FindLoops menggunakan penyimpanan sebelumnya,
bila memungkinkan.
(Pada kenyataannya, dalam makalah Hundt tersebut, dia menjelaskan bahwa
program Java membutuhkan perubahan ini supaya kinerjanya cukup bagus, tetapi
ia tidak melakukan perubahan yang sama pada implementasi di bahasa yang
menggunakan garbage-collected yang lain.)
Kita akan tambahkan sebuah struktur cache global:
var cache struct {
size int
nonBackPreds [][]int
backPreds [][]int
number []int
header []int
types []int
last []int
nodes []*UnionFindNode
}
dan kemudian membuat FindLoops menggunakannya sebagai pengganti alokasi:
if cache.size < size {
cache.size = size
cache.nonBackPreds = make([][]int, size)
cache.backPreds = make([][]int, size)
cache.number = make([]int, size)
cache.header = make([]int, size)
cache.types = make([]int, size)
cache.last = make([]int, size)
cache.nodes = make([]*UnionFindNode, size)
for i := range cache.nodes {
cache.nodes[i] = new(UnionFindNode)
}
}
nonBackPreds := cache.nonBackPreds[:size]
for i := range nonBackPreds {
nonBackPreds[i] = nonBackPreds[i][:0]
}
backPreds := cache.backPreds[:size]
for i := range nonBackPreds {
backPreds[i] = backPreds[i][:0]
}
number := cache.number[:size]
header := cache.header[:size]
types := cache.types[:size]
last := cache.last[:size]
nodes := cache.nodes[:size]
Penggunaan variabel global seperti di atas adalah praktik rekayasa yang jelek:
artinya pemanggilan konkuren ke FindLoops sekarang tidak aman lagi.
Untuk saat sekarang, kita membuat perubahan sekecil mungkin untuk memahami apa
saja yang penting bagi kinerja dari program kita;
perubahan ini cukup sederhana dan mirip dengan implementasi pada Java.
Versi akhir dari program Go akan menggunakan instan LoopFinder yang terpisah
untuk melacak penggunaan memori ini, supaya dapat digunakan secara konkuren.
$ make havlak5 go build havlak5.go $ ./xtime ./havlak5 # of loops: 76000 (including 1 artificial root node) 8.03u 0.06s 8.11r 770352kB ./havlak5 $
(Lihat
perubahan untuk havlak4)
Ada banyak lagi yang dapat kita lakukan untuk membersihkan program dan
membuatnya lebih cepat, tetapi tidak ada lagi yang membutuhkan teknik profil
seperti yang telah kita perlihatkan.
Daftar hasil yang digunakan dalam pengulangan dapat digunakan kembali selama
iterasi dan selama pemanggilan ke FindLoops, dan ia bisa digabungkan
dengan "node pool" terpisah yang dibangkitkan selama berjalan.
Hal yang sama, penyimpanan "loop graph" dapat dipakai ulang pada setiap
iterasi bukan dengan mengalokasikan kembali.
Selain perubahan kinerja,
versi terakhir
ditulis menggunakan gaya idiomatis Go, menggunakan struktur data dan method.
Perubahan kode hanya memiliki efek minor pada run-time: algoritme dan
batasan-batasannya tidak berubah.
Versi terakhir berjalan dalam 2.29 detik dan menggunakan 351 MB memori:
$ make havlak6 go build havlak6.go $ ./xtime ./havlak6 # of loops: 76000 (including 1 artificial root node) 2.26u 0.02s 2.29r 360224kB ./havlak6 $
Lebih cepat 11 kali daripada program yang pertama. Bahkan bila kita memakai ulang loop graph hasil pembangkitan, sehingga yang di cache hanya pencatatan pencarian pengulangan, program tersebut masih tetap 6.7x lebih cepat dari yang asli dan menggunakan 1.5x memori lebih sedikit.
$ ./xtime ./havlak6 -reuseloopgraph=false # of loops: 76000 (including 1 artificial root node) 3.69u 0.06s 3.76r 797120kB ./havlak6 -reuseloopgraph=false $
Tentu saja, sudah tidak adil lagi membandingkan program Go dengan program C yang aslinya, yang menggunakan struktur data yang tidak efisien seperti `set` yang mana `vector` sebenarnya lebih cocok. Untuk pemeriksaan, kami menerjemahkan program Go yang terakhir ke https://github.com/rsc/benchgraffiti/blob/master/havlak/havlak6.cc[kode C yang sama^]. Waktu eksekusi mirip dengan program Go:
$ make havlak6cc g++ -O3 -o havlak6cc havlak6.cc $ ./xtime ./havlak6cc # of loops: 76000 (including 1 artificial root node) 1.99u 0.19s 2.19r 387936kB ./havlak6cc
Program Go berjalan hampir sama cepatnya dengan program C. Bila program C menggunakan alokasi dan penghapusan secara otomatis bukan cache, program C++ sedikit lebih cepat dan mudah ditulis, tetapi tidak begitu jauh perbedaannya:
$ wc havlak6.cc; wc havlak6.go 401 1220 9040 havlak6.cc 461 1441 9467 havlak6.go $
(Lihat havlak6.cc dan havlak6.go )
Hasil dari sebuah benchmark sama bagusnya dengan program yang diukur. Kita menggunakan "go tool pprof" untuk mempelajari program Go yang tidak efisien dan kemudian meningkatkan kinerjanya lebih cepat dan mengurangi penggunaan memori 3.7x lebih sedikit. Pembandingan dengan program C yang sama memperlihatkan bahwa Go dapat berkompetisi dengan C bila pemprogram berhati-hati dengan berapa banyak garbage dihasilkan dalam pengulangan.
Sumber kode program, binari-binari Linux x86-64, dan profil-profil yang digunakan untuk menulis artikel ini tersedia di proyek benchgraffiti di Github.
Seperti yang telah disebutkan juga di atas,
go test
sudah mengikutkan kedua opsi profil tersebut: definisikan sebuah
fungsi benchmark
dan ia sudah siap digunakan.
Terdapat juga standar HTTP interface untuk mendapatkan data profil.
Dalam sebuah server HTTP, menambahkan
import _ "net/http/pprof"
akan memasang handler untuk beberapa URL di bawah /debug/pprof/.
Kemudian Anda tinggal jalankan "go tool pprof" dengan sebuah parameter—URL
ke profil data server Anda—dan ia akan mengunduh dan memeriksa profil secara
langsung.
go tool pprof http://localhost:6060/debug/pprof/profile # profil CPU 30-detik go tool pprof http://localhost:6060/debug/pprof/heap # profil heap go tool pprof http://localhost:6060/debug/pprof/block # profil menutup goroutine
Profil yang menutup goroutine akan dijelaskan di artikel selanjutnya.